

近年来,AIGC 工具已经成为自媒体、企业内容运营和品牌营销的重要生产力。无论是公众号文章、知乎干货、企业新闻稿,还是短视频口播脚本,越来越多内容团队开始借助大模型完成初稿生成、资料整理和表达优化。
但与此同时,一个新的问题也开始浮出水面:内容生产效率提高了,文章却变得越来越“像 AI 写的”。
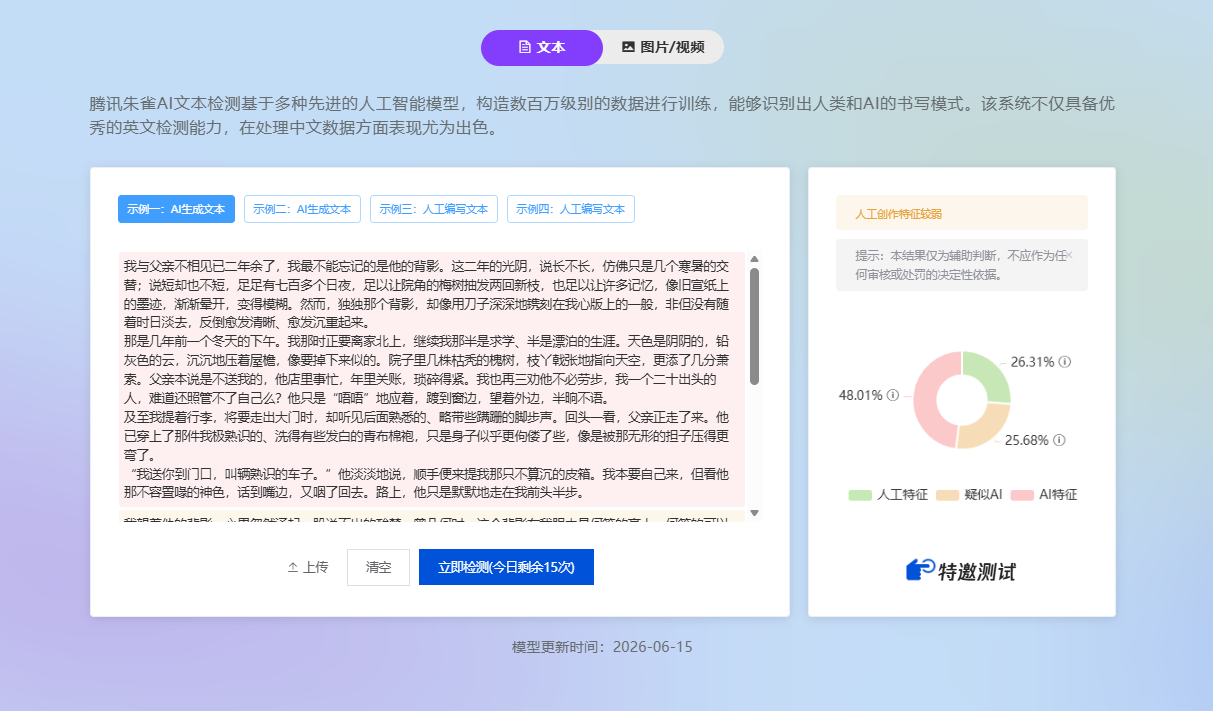
不少创作者发现,明明文章没有违规,也没有夸张营销,但发布后推荐量下降、阅读量不稳定,甚至被系统提示内容质量较低。尤其在公众号生态里,“朱雀系统”“AI 味检测”“内容风控”“限流扣分”等关键词,已经成为很多内容创作者反复搜索的问题。
那么,平台为什么会识别出一篇文章存在较强 AI 痕迹?所谓“朱雀检测”到底可能关注哪些文本特征?AIGC 内容又该如何从源头降低机械感,回到更自然、更真实、更适合传播的表达状态?
这正是当前内容行业需要重新审视的问题。
一、AI 味不是简单的几个词,而是一整套文本特征
很多人以为,所谓 AI 味,就是文章里出现了“首先、其次、总之、值得注意的是”这些高频连接词。于是他们会简单地删词、换词、打乱语序,甚至用同义词替换工具重新改一遍。
但从实际内容风控逻辑来看,AI 痕迹往往并不是某几个词造成的,而是一整套文本结构共同形成的结果。
一篇明显带有 AI 味的文章,通常会有几个典型特征:
第一,句子过于规整。
很多 AI 生成文章喜欢使用相似长度、相似结构的句子。每一段都像经过统一模板加工,读起来很顺,但缺少真实作者的停顿、犹豫、转折和表达起伏。
第二,逻辑推进过于完整。
真实创作者写文章时,往往会有轻重缓急,有些地方会展开,有些地方会一笔带过。而 AI 文章经常把每个观点都讲得过于均衡,段落之间像标准答案,缺少人的思考痕迹。
第三,表达密度过于稳定。
人写文章会有情绪波动,也会有局部口语、短句、插入语和不完全对称的表达。而 AI 生成内容往往语义密度稳定、信息分布平均,整篇文章看起来“正确”,但缺少真实内容的颗粒感。
第四,段落模板化明显。
比如开头先提出背景,中间列出几个原因,结尾再总结升华。这种结构并没有错,但如果大量文章都遵循同样的节奏,就容易被平台识别为模板化内容。
第五,文本概率分布过于顺滑。
大模型生成文本时,会倾向于选择概率较高、逻辑更顺、表达更安全的词语组合。这会导致文章看起来通顺,但语言轨迹过于可预测。对平台风控系统来说,这类文本往往更容易被识别为机器生成内容。
因此,AI 味不是简单的“有没有 AI 词”,也不是“通顺不通顺”,而是句式、词序、段落、节奏、语义密度和表达轨迹共同形成的结果。
二、为什么简单改写很难真正解决问题?
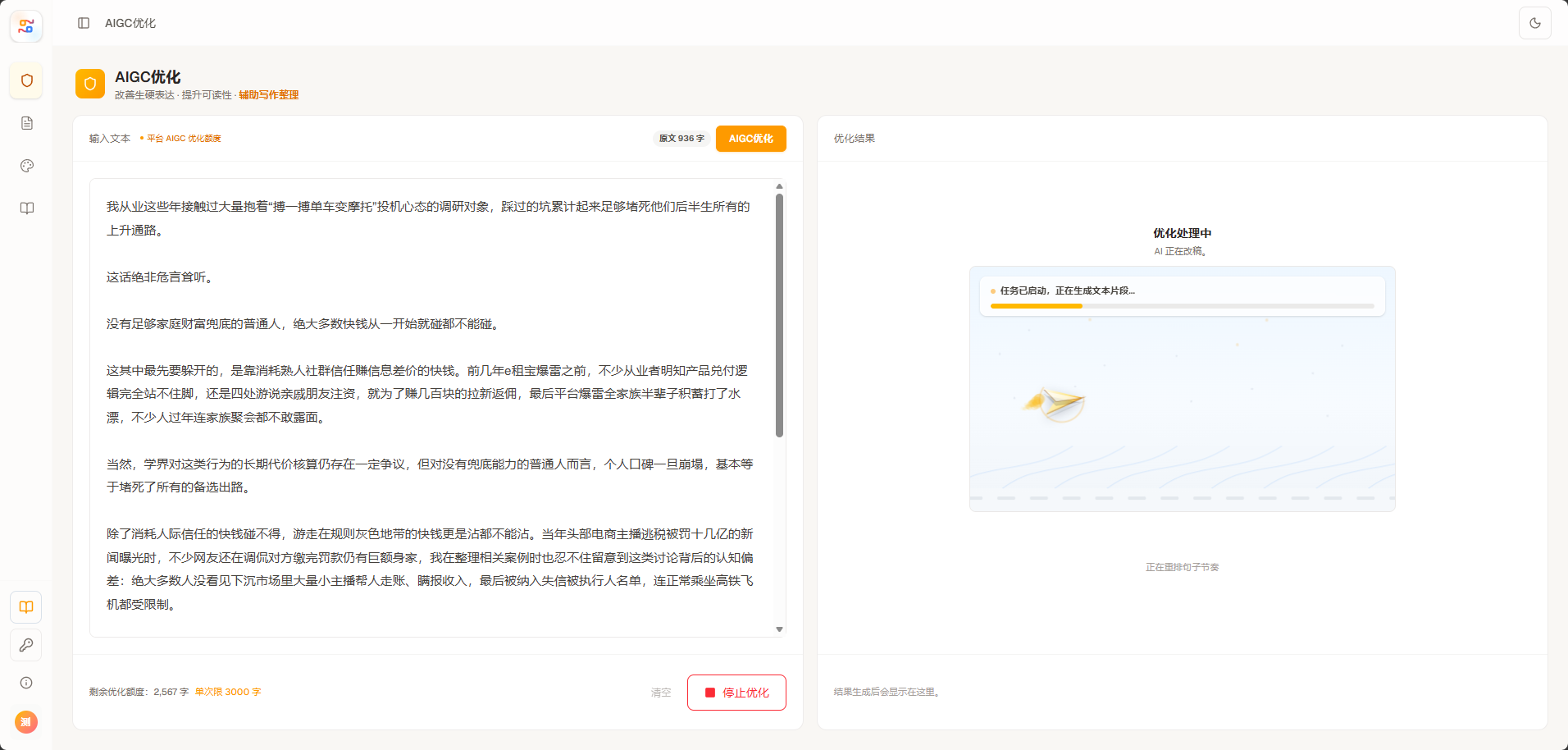
面对 AI 味过重的问题,很多创作者的第一反应是再丢给另一个 AI 工具改写一遍。
但这类操作经常会出现两个问题。
一种情况是,文章确实变得不一样了,但依然很像 AI。因为它只是把原来的词换了一批,把句子重新排列了一下,本质上仍然保留了大模型生成内容的顺滑轨迹。
另一种情况是,AI 痕迹下降了一些,但文章读起来变乱了。事实信息丢失,排版结构错乱,标题层级被打散,甚至出现语义前后不连贯的问题。
这也是很多内容团队的真实痛点:
只追求“降低 AI 味”,文章容易变得难读;
只追求“读起来顺”,又容易重新回到 AI 模板感。
尤其对于公众号长文、知乎干货、企业品牌稿这类内容来说,文章不是几十个字的短句,不能靠简单替换解决问题。长文的 AI 痕迹往往藏在整体结构里,包括段落推进方式、观点展开节奏、句子内部词序、信息密度分布和总结句模式。
也就是说,真正的 AIGC 内容优化,需要从更底层的文本结构入手。
三、从“改词”到“重构”:词元共振技术的出现
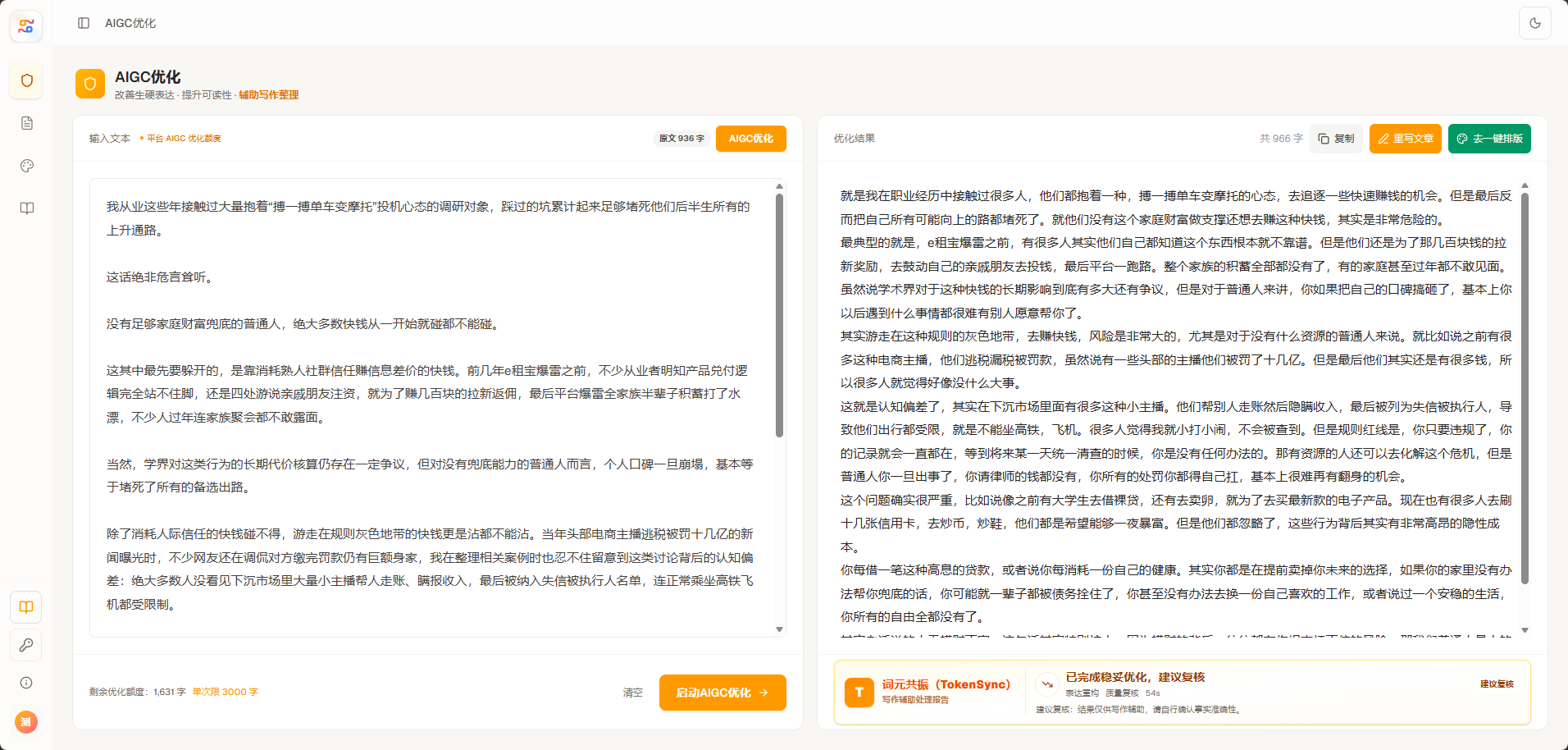
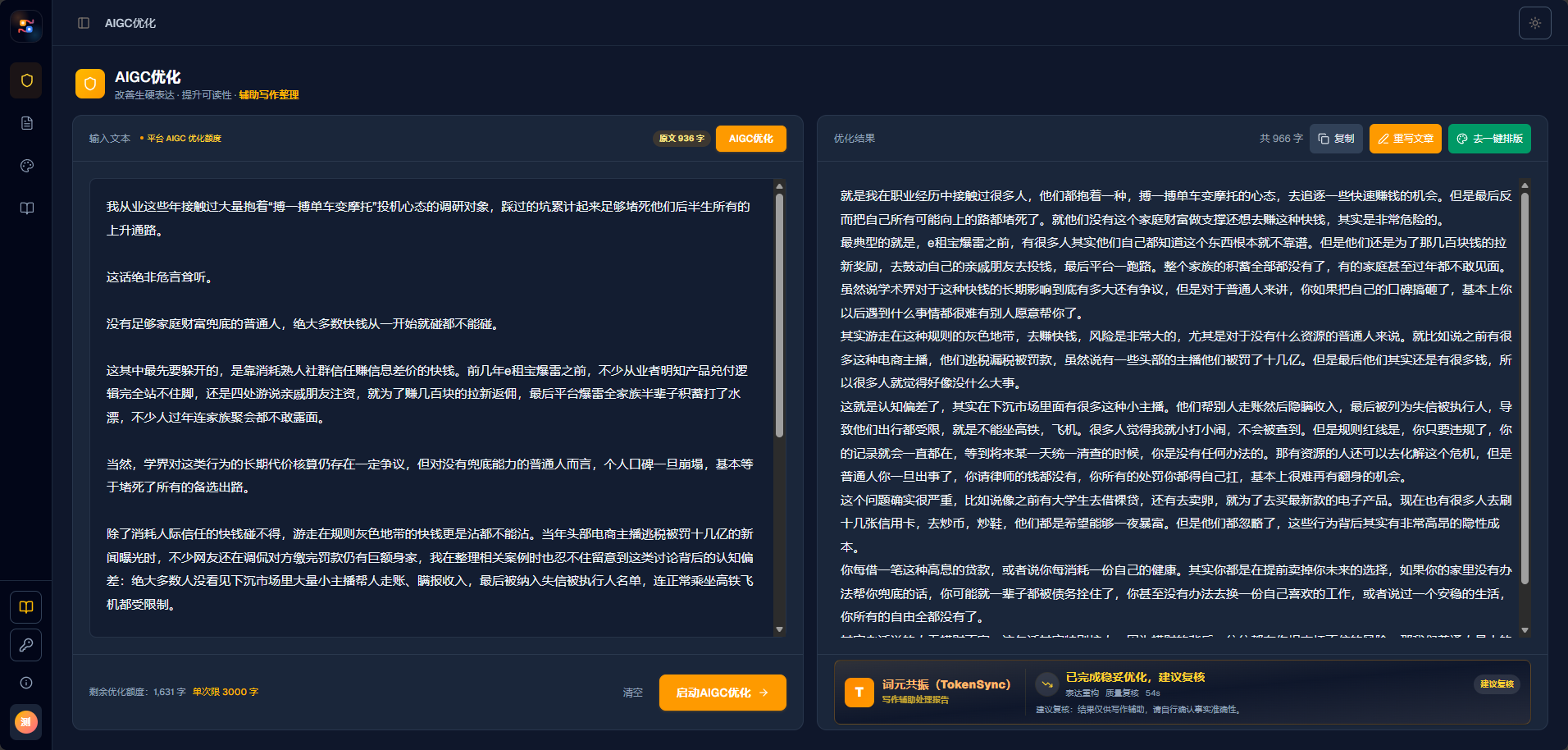
在这样的背景下,TokenSync(词元共振)提出了一种新的内容优化思路:不把 AIGC 优化理解为简单的同义词替换,而是从 Token 级语义结构、句式节奏、段落轨迹和排版保护等多个维度,对文本进行重新组织。
Token 是大模型处理语言时的基本单位。通俗理解,一篇文章在模型眼中并不是一个个完整汉字或词语,而是一串具有概率关系的语言片段。AI 文章之所以容易显得“顺滑”“规整”“模板化”,正是因为这些语言片段之间的连接方式过于稳定。
词元共振技术关注的不是表层替换,而是文本底层轨迹的变化。
它更强调几个方向:
第一,调整句子内部的词序稳定性。
不是简单把“提高效率”换成“提升效率”,而是重塑句子表达节奏,让句子不再呈现统一的机器式结构。
第二,改变段落之间的推进方式。
真实文章往往不是每一段都均匀展开。词元共振会在保留原意的基础上,重新组织段落节奏,让内容更接近真人写作的自然推进。
第三,降低高频 AI 句式和模板痕迹。
例如过度标准化的总结句、并列式论证、机械转折、固定开头结尾等,都会被识别并做针对性优化。
第四,保持语义真实,不盲目打乱内容。
AIGC 优化不是把文章改得越乱越好。真正可用的优化结果,必须同时保留事实、逻辑、风格和可读性。
第五,保护 Markdown 与文章排版结构。
很多内容团队最怕的一点是,文章优化后标题、加粗、列表、引用、分段全部乱掉。TokenSync 在设计上加入了 Markdown 结构保护解析,尽量让内容优化和排版稳定同时完成。
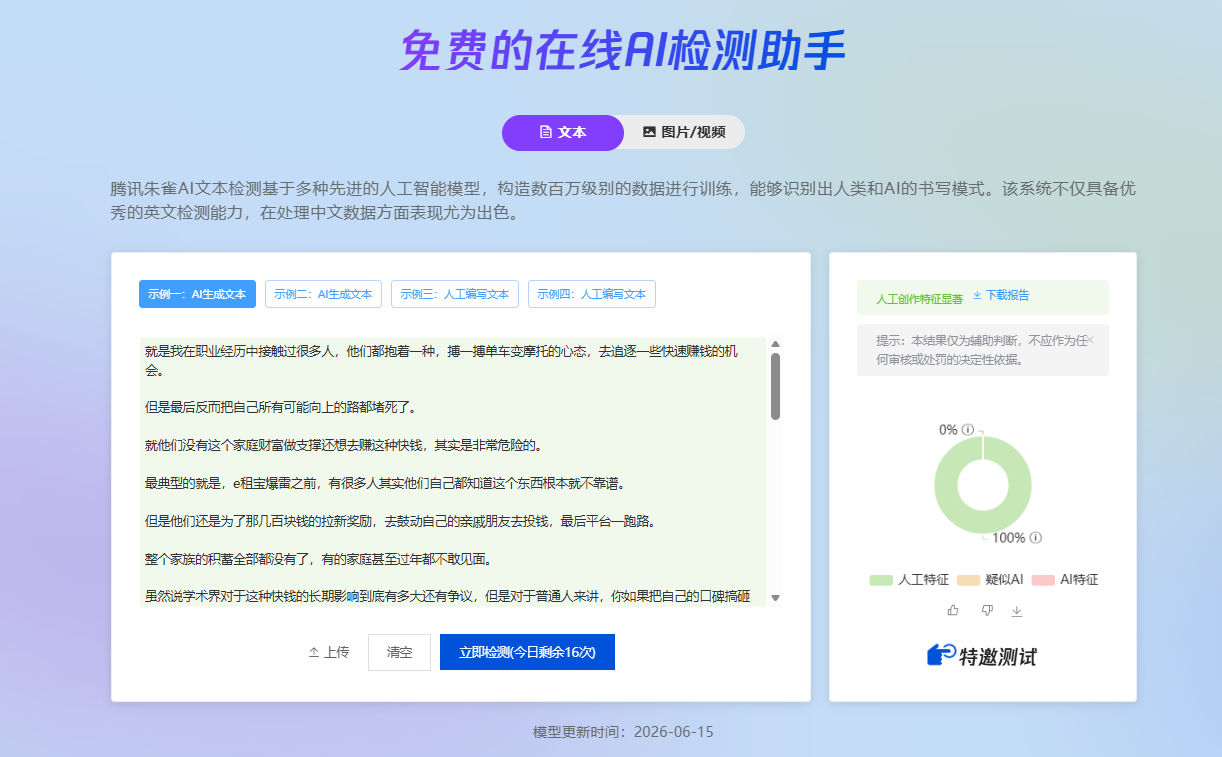
四、面对朱雀系统,内容优化的重点不是“绕过”,而是降低机器写作特征
很多创作者搜索“怎么过朱雀检测”,本质上并不是想违规,而是希望自己的正常内容不要因为 AI 痕迹过重而被误判、限流或降低推荐。
从平台治理角度看,内容风控的目标不是打击工具本身,而是筛掉低质、批量、模板化、缺少原创表达的内容。因此,创作者真正需要做的,不是寻找所谓的“破解方法”,而是把文章从机械生成状态,优化成更符合真实创作者表达习惯的内容。
这其中有几个关键点:
不要只改词,要改节奏。
不要只追求通顺,要保留人的表达起伏。
不要只降低检测数值,还要保留文章原本的信息价值。
不要为了降低 AI 味,把内容改得语义错乱。
不要忽略排版,因为格式混乱会直接影响发布效率和阅读体验。
这也是 TokenSync 适合公众号长文、知乎干货、企业品牌稿、自媒体日更内容的原因。它的目标不是制造低质伪原创,而是帮助创作者对 AI 初稿进行深度优化,让内容更自然、更稳定、更适合正式发布。
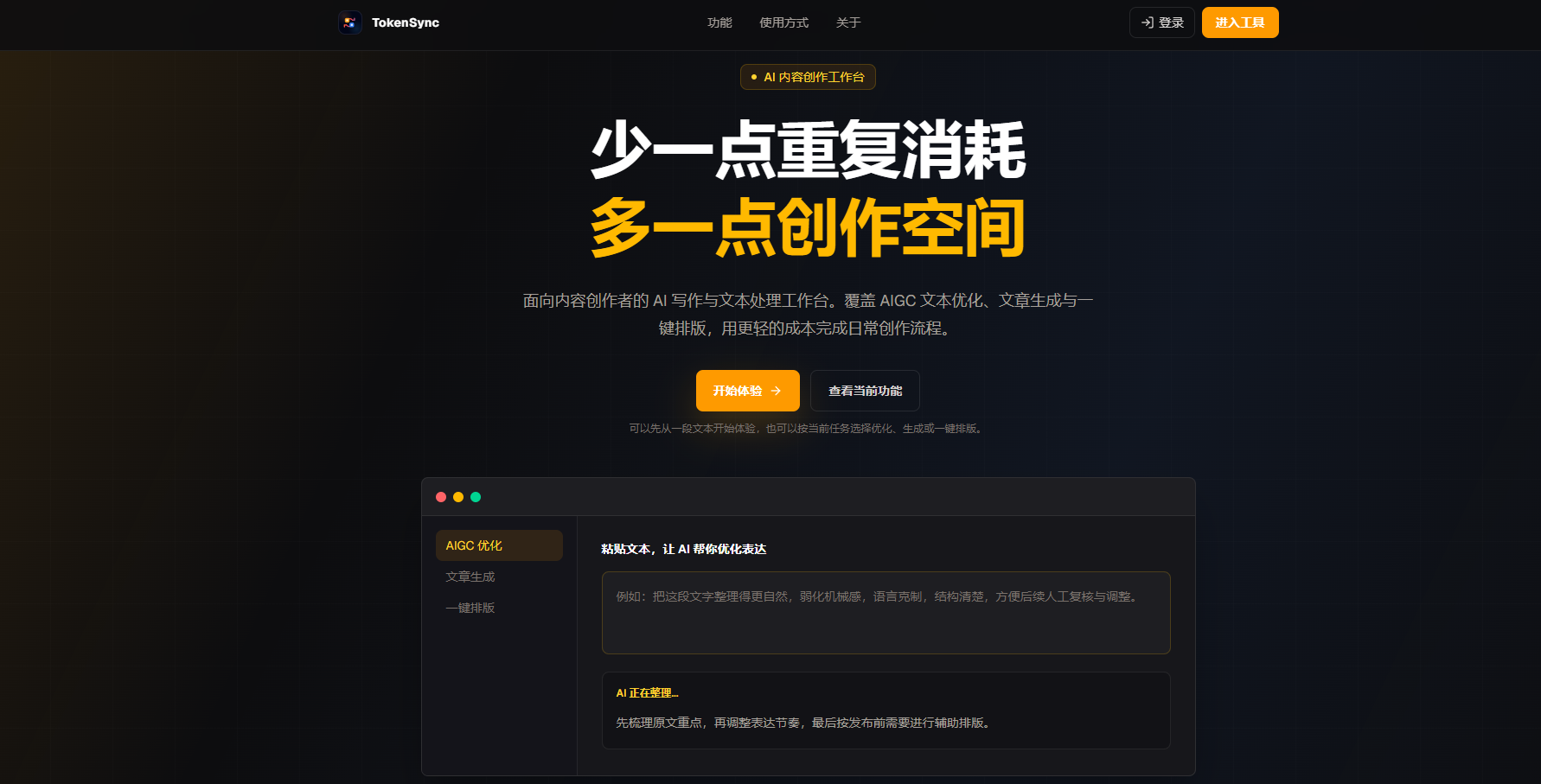
五、TokenSync 适合哪些内容场景?
从实际使用场景来看,TokenSync 更适合以下几类用户:
第一类,是公众号等自媒体创作者。
很多公众号作者会用 AI 辅助写初稿,但又担心文章 AI 味太重,影响平台分发。对于 800 字、1500 字、3000 字以上的长文来说,普通改写工具很难处理整体结构问题,而 TokenSync 更适合做深度文本重构。
第二类,是知乎、小红书、头条等平台的内容运营者。
这些平台对内容原创度、可读性和账号质量都有要求。长期依赖 AI 生成内容,如果不做优化,很容易形成统一的机器写作风格。
第三类,是企业品牌和市场团队。
企业官网文章、品牌稿、新闻稿、招商文案,经常需要借助 AI 提高生产效率。但企业内容更重视专业感和可信度,如果 AI 味过重,会影响品牌形象。
第四类,是批量日更账号和内容团队。
当一个团队每天需要生产多篇内容时,单靠人工逐句修改成本太高。TokenSync 的 BYOK 模式支持用户接入自己的大模型 API 密钥,在控制成本的同时完成批量文本优化,更适合长期内容生产场景。
第五类,是重视格式稳定的创作者。
很多文章本身已经做好了标题、列表、加粗、引用等 Markdown 结构。如果优化工具破坏排版,后期重新整理会非常耗时。TokenSync 的格式保护能力,能明显减少这类重复劳动。
六、AIGC 内容优化将从“能生成”走向“能发布”
过去一年,内容行业最关注的是 AI 能不能写。
但现在,真正的问题已经变成:AI 写出来的内容能不能安全、自然、稳定地发布。
对于自媒体和企业来说,AIGC 内容不能只停留在生成阶段,还需要经过事实校对、语义优化、风格调整、AI 味降低和排版整理,才能进入正式发布流程。
这意味着,未来的内容工具不再只是“帮你写一篇文章”,而是要帮你把文章处理到更接近可发布状态。
TokenSync(词元共振)正是围绕这个方向构建的 AI 文本优化平台。它聚焦于 AI 味过重、平台内容风控、朱雀系统识别、Markdown 排版丢失、批量长文优化等真实痛点,为自媒体创作者和企业内容团队提供一套更底层的文本重构方案。
对于已经使用 AI 写作的创作者来说,未来的竞争不只是“谁生成得更快”,而是“谁能把 AI 初稿优化得更像真实内容”。
这也是 AIGC 内容生态进入下一阶段的重要变化。
七、结语
随着平台内容治理越来越精细,简单堆量、简单改写、模板化生成的内容空间会越来越小。真正有价值的工具,不是鼓励低质伪原创,而是帮助创作者在提高效率的同时,保留真实表达、内容价值和发布稳定性。
从这个角度看,围绕 Token 级语义重构、文本轨迹优化和排版结构保护展开的词元共振技术,正在成为 AIGC 内容优化的重要方向。
对于正在被 AI 味、朱雀检测、公众号限流、文章排版混乱困扰的创作者来说,TokenSync 提供了一种新的解决思路:不是简单换词,而是让文本重新回到更自然、更像真人写作的状态。
TokenSync 官网:tokensync.cn
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
- AIGC内容进入精细化风控时代:从“朱雀检测”看文本优化的新方向(2026-07-02)
- 夯实长护险专业照护能力:浙江易得康首期认知症护理技能培训顺利结课(2026-07-02)
- 丝路纵横,越野破局|福田火星9越野版亮相亚欧博览会(2026-06-30)
- 走,去河北研学! 第四届河北省研学旅游交流活动(2026-06-30)
- 赋能日照“体育+”高质量发展 2026中国运动休闲大会启幕(2026-06-29)
- AIGC内容进入精细化风控时代:从“朱雀检测”看文本优化的新方向(2026-07-02)
- 在兰州看黄河的慢与快-看热讯(2026-07-02)
- 五座城共读一本书(2026-07-02)
- 热推荐:金融 AI 实测|MiniMax 内置企查查 MCP:企业查询、股权穿透与UBO识别效果如何?(2026-07-02)
- 时讯:*ST益通:正积极推进脑机接口产品的医疗器械注册工作(2026-07-02)
- 2025/26榨季国产糖最终产量1296.6万吨_热门看点(2026-07-02)
- 银行手续费有哪些常见类型需注意?_热点(2026-07-02)
- 大涨触发临停!华润新能源上市,为深交所史上最大IPO(2026-07-02)
- 滚动:卓创资讯与瑞柏集团签署战略合作协议(2026-07-02)
- 夯实长护险专业照护能力:浙江易得康首期认知症护理技能培训顺利结课(2026-07-02)
- 鸿宇汇(海南)网络科技获双项品牌大奖 数字创新赋能实体经济(2026-07-02)
- 瑞威资管(01835.HK)今早复牌(2026-07-02)
- 先声药业(02096.HK)再涨近9%,截至发稿,涨7.92%,报10.63港元,成交额1503.86万港元_最新快讯(2026-07-02)
- 【播资讯】港股科网股反弹 美团涨近7%(2026-07-02)
- 2026年“匠心众运”车辆模型文化系列赛事活动(青岛站)成功举办——实现汽车产业与车辆模型运动“价值共创”(2026-07-02)
- 7月2日生意社线材基准价为3325.00元/吨(2026-07-02)
- 今日视点:车辆高频使用需缩短保养周期吗?(2026-07-02)
- 冷却液更换周期需根据什么确定?(2026-07-02)
- 纸卷搬运不再“卷”,一图解锁纸卷及二级包装林德自动化解决方案(2026-07-01)
- 纸卷搬运不再“卷”,一图解锁纸卷及二级包装林德自动化解决方案(2026-07-01)
- 天岳先进: 关于持股5%以上股东权益变动触及1%刻度的提示性公告|每日精选(2026-07-01)
- 和讯李国培:明天是否冲高回落?(2026-07-01)
- 国内期货夜盘开盘多数下跌 LPG跌超3%_焦点速读(2026-07-01)
- 焦点精选!行云科技:控股子公司签订总金额55.08亿元算力服务合同(2026-07-01)
- 7月1日生意社PP市场基差为744元/吨(2026-07-01)
- 生意社玻璃7月1日均差为-0.07元/平方米 由负向缩小重新扩大(2026-07-01)
- 当前关注:7月1日华映科技涨停:福建自贸/海西概念,自贸区,国企改革概念热股(2026-07-01)
- 今日看点:7月1日启明信息涨停:数据要素,国产软件,胎压监测概念热股(2026-07-01)
- 信息:怎样减少智能驾驶系统的用户误操作?(2026-07-01)
- 双城嘉年华丨中国人寿织保障网,“东北超”赛事护航无忧-每日短讯(2026-07-01)
热点排行
- 1 “筑梦乡村振兴·共绘花果三台”——三台县水果现代农业园区正式开园
- 2 苗博士毕格赛省麦种测产全国观摩会 引发社会热议
- 3 北京链家召开“客户日” 安心服务承诺累计退赔10.7亿元
- 4 跑上跑下帮居民解急难事 房屋中介小哥就地变身志愿者
- 5 北京链家长期开放“户外劳动者暖心驿站”前路或有风雨,请让我为你把“伞”撑起
- 6 协助解除弹窗、分发物资 北京链家志愿者加入潘家园、劲松防疫
- 7 孩子居家隔离功课不能耽误!东城志愿者跑腿代买试卷打印资料
- 8 北京管控区一宝宝生病,志愿者当“闪送员”跑了多家医院……
- 9 焦点品牌咨询探索突破营销困局,拓展品牌传播新模式
- 10 金九银十清洁季,还不抓紧入手一款省心的清洁工具?




关于我们| 客服中心| 广告服务| 建站服务| 联系我们
中国焦点信息网 版权所有 沪ICP备2022005074号-20,未经授权,请勿转载或建立镜像,违者依法必究。